
Retention Index (RI) values can be a powerful tool to assist in the unknown identification of organic compounds provided the RI of the unknown compound is available. NIST has updated and maintained a compound database of measured RI values for almost 140,000 compounds . In addition, NIST has recently developed an artificial intelligence (AI) model which can calculate RI from the chemical structure with high accuracy providing RI values for nearly all of the over 300,000 compounds in the Electron Ionization Mass Spectrometry (EI-MS) database. While RI values alone cannot necessarily uniquely identify unknow compounds, when coupled with Library searching (x) for the EI-MS database, a much higher level of confidence of unknown identification can be achieved than by either technique alone.
To correctly calculate RI values for unknowns one must carefully run a calibration of known compounds, usually an n-alkane ladder, under identical conditions as the sample will be run. This includes flow rate, temperature program, inlet temperature, column, etc. As the RI values will be calculated by interpolation between the RI standards, it is optimal to have the standards spaced relatively evenly and close together across the chromatographic run. Any changes in the method or conditions will require re-running the RI calibration. Thus, the downside of this approach is the additional time and effort to routinely re-run the calibration sample on a regular basis adding additional burden and less efficiency for the analyst. Internal RI calibrations are also possible, but can be problematic, especially for complex samples, due to interference and overlap of the standards peaks with the sample peaks.
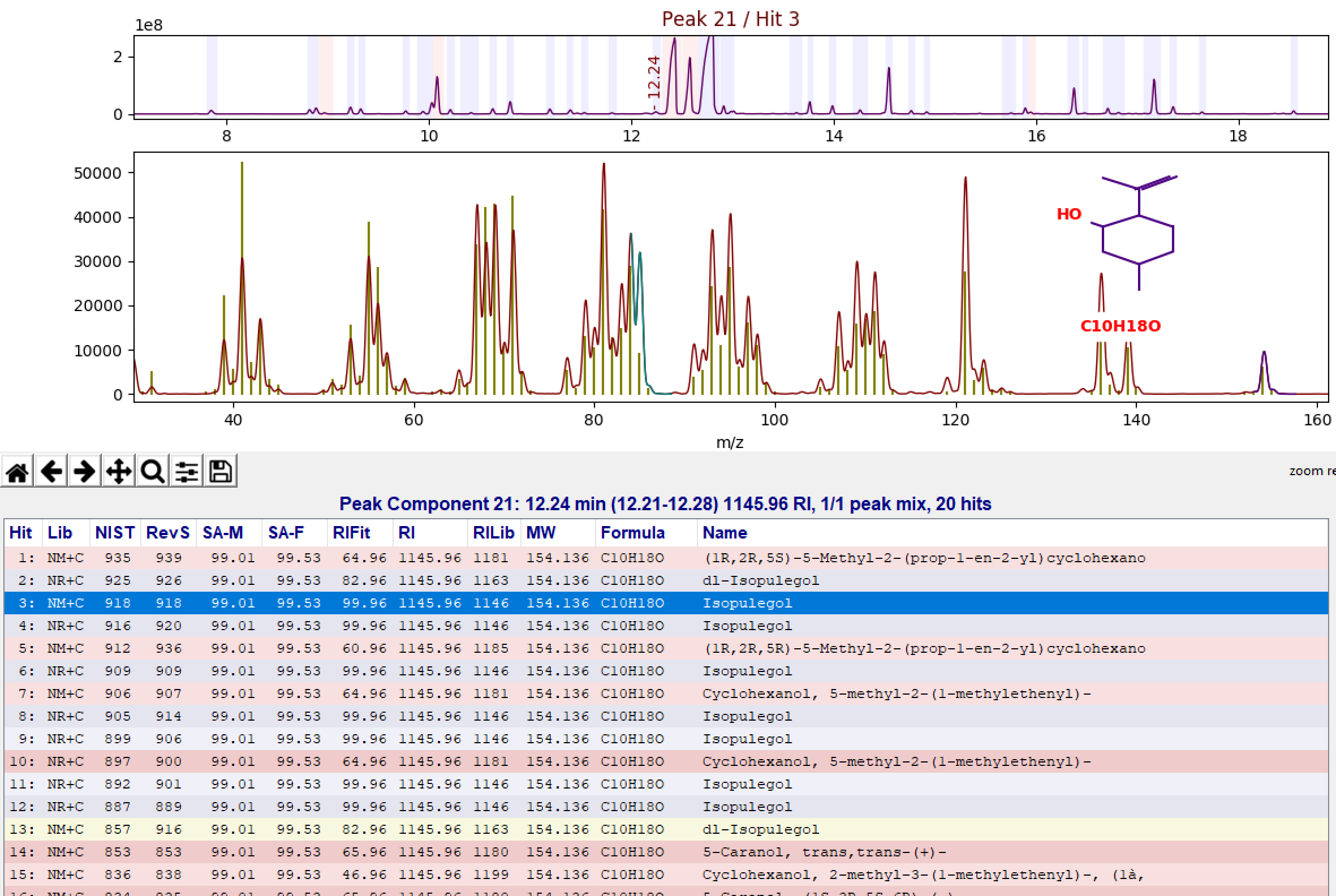
By comparing the RI of the unknown (RI) to the Library RI (RILib) we can easily correctly identify the correct compound as the third match in the NIST Hit list.
By comparing the RI of the unknown (RI) to the Library RI (RILib) we can easily correctly identify the correct compound as the third match in the NIST Hit list.
AutoRI™ is a patented system for automatic Retention Index calibration without the need to run any standards saving you time and enabling enhanced analysis of previously collected data. Auto RI uses the unknown sample itself by using peaks identified with high confidence through library search to calibrate the RI for the run. At least 2 criteria are used to identify compounds in the run to use as RI calibration standards. The first, the quality of the GC/MS search match values (“match”) is used to tentatively identify each peak. The reverse search value is also compared to the forward search to estimate the purity of the peak, and hence a further vote of confident ID. The second, is the relative retention time of other tentatively identified peaks located before and after the target calibration peak. This is done by plotting the compounds known RI values (available from the NIST database) of the tentatively identified peaks as a function of RT and performing a least squared fit of all candidates. This process can be used to identify a well-spaced set of internal calibration peaks to accurately calibrate the run for RI. Once calibrated, RI values for all peaks in the run can be assigned to aid in compound identification. The flow of the process is as follows:
- Pick all peaks in the chromatogram run (mixture deconvolution to identify compounds in co-eluting peaks optional)
- Perform Library Search on each peak (or pure compound by deconvolution) to generate a “Hit List” ranked by search match quality
- Evaluate each match in the “Hit List” above a specified “good” threshold and (optional) where the difference between Forward Search the Reverse Search falls withing a specified limit (an indication of purity) to produce a list of highly probable identifications.
- Use a graphical plot and perform least squares fit of the known RI of each identified compound vs its Retention Time, note that a multitude of mathematical methods may also be used to detect “outliers”
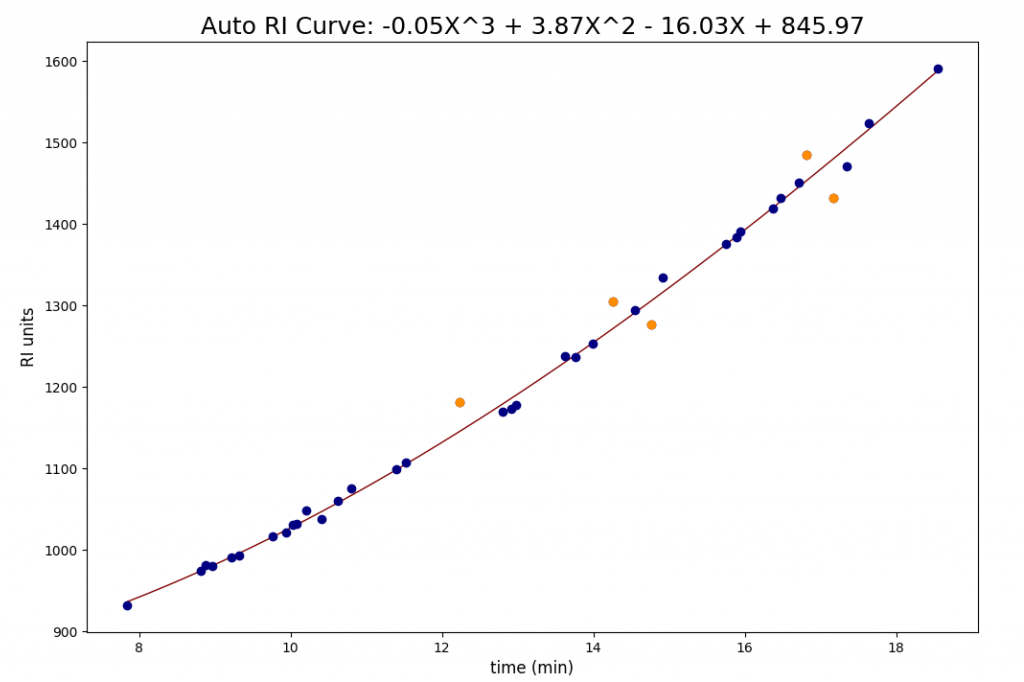
- Identify “outliers” that deviate significantly from the least squares fit using, for example, a standard deviation cutoff or other statistical method
- Remove outliers from the data set
- Repeat least squares fit or other mathematical approach to remaining data set until the data is statistically consistent
- Map the fitted least squares fitted curve to the RT of all compounds in the run to calculate there RI values
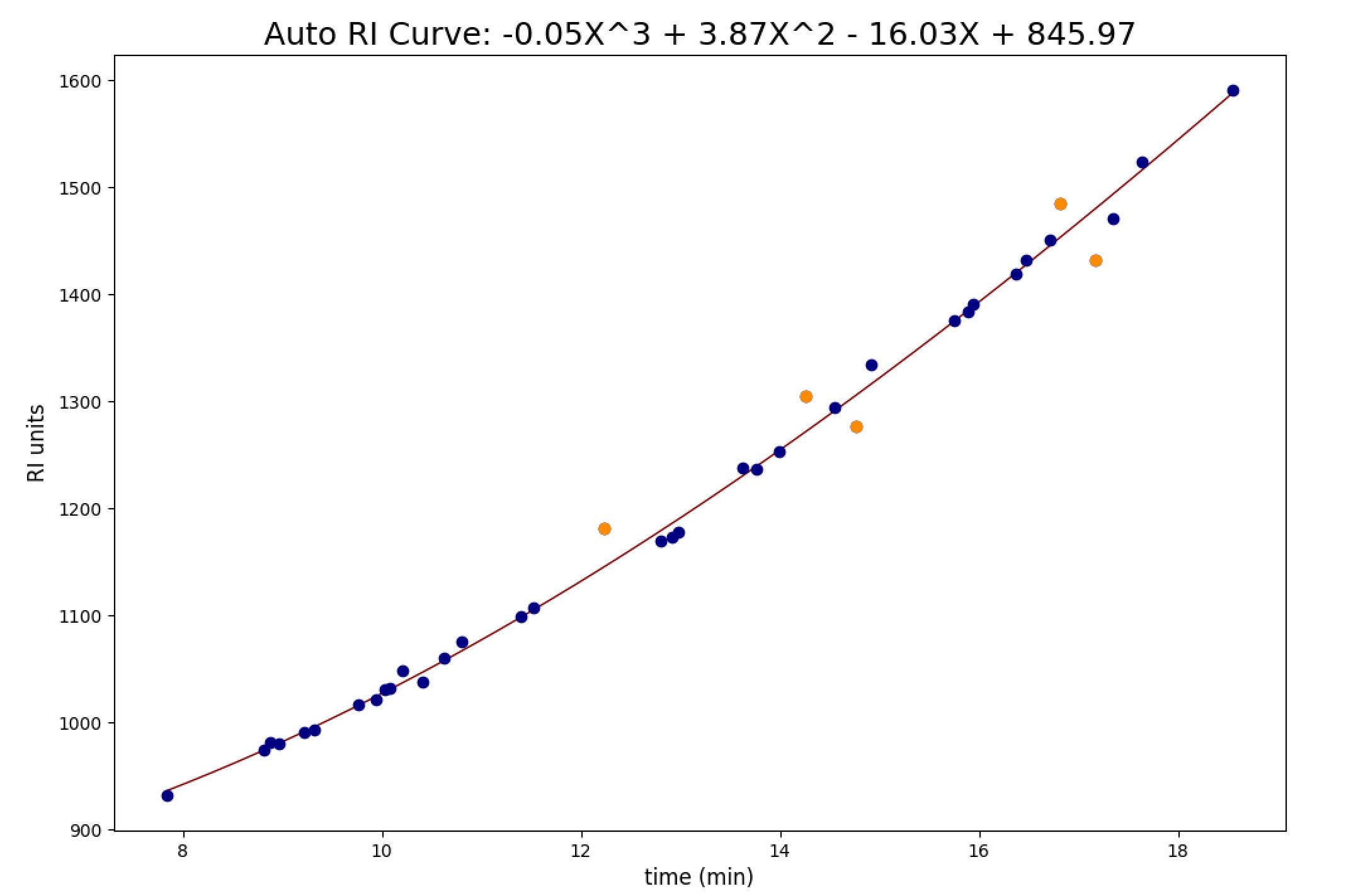
Auto RI locates high quality compound matches from the search and generates an initial RI calibration. It then eliminate statistically significant outliers that do not follow a logical RI trend.
Auto RI locates high quality compound matches from the search and generates an initial RI calibration. It then eliminate statistically significant outliers that do not follow a logical RI trend.
Sounds good. Does it really work, can I trust it?
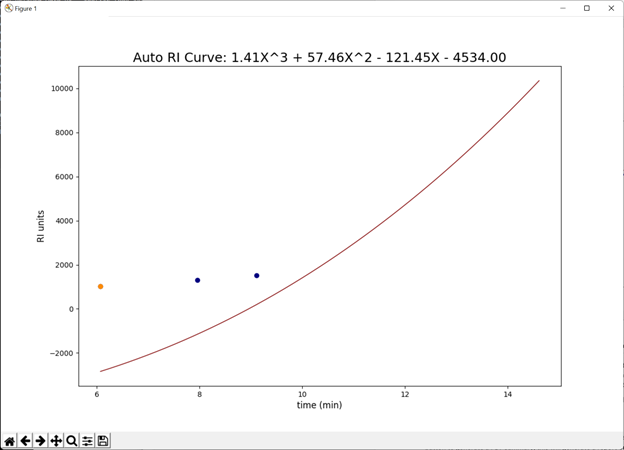
This method has been shown to be reliable and accurate for a majority of samples. It cannot be used on samples that only contain a few peaks across the run that can be identified by search as correct with a high degree of confidence. It is very simple to determine if Auto RI is working well for your data by inspecting the RI curve generated. If there are too few high confidence compounds identified in your sample, there may not be enough data to generate a confident RI calibration. The graph to the right is an example of an Auto RI curves with too few samples, and in such cases, RI data should not be considered.
One of the many powerful features of MassWorks GC/ID.
Find out more from the GC/ID brochure.
{kind=link}
{kind=link}